Whisper - audio/video text extraction and automatic subtitles
Whisper is an open-source automatic speech recognition (ASR) system developed by OpenAI. It can transcribe audio and video files into text using advanced deep learning models, all while running entirely on your own server.
Whisper is local and private
Unlike many cloud-based transcription services, Whisper runs locally on your server. No audio data is uploaded to OpenAI or any other third party. This ensures that:
- No sensitive media files leave your server
- Whisper can be used in secure or offline environments
- It complies with strict data protection policies (e.g., GDPR)
The Whisper plugin for ResourceSpace uses this local installation to extract text and subtitles from supported audio and video files.
System requirements
To run Whisper from the command line and enable the plugin functionality, the following software must be installed:
- Python 3.8 or higher
- FFmpeg
- Git
- OpenAI Whisper
- PyTorch (with or without GPU support)
Installation instructions (Ubuntu/Debian)
1. Update the package list and install dependencies
sudo apt update
sudo apt install -y python3 python3-pip ffmpeg git
2. Install PyTorch
Whisper depends on the PyTorch machine learning library.
For CPU-only systems:
pip3 install torchFor systems with an NVIDIA GPU:
Visit pytorch.org to select the correct installation command for your system. Example:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1183. Install Whisper
pip3 install -U openai-whisper4. Verify Installation
whisper --helpTo test transcription on a file:
whisper path/to/audio.wav --model baseThis should generate .txt, .srt, and .vtt output files in the same directory.
5. Ensure Whisper is in the system PATH
If whisper is not available globally, ensure ~/.local/bin is in your PATH, or symlink manually:
sudo ln -s ~/.local/bin/whisper /usr/local/bin/whisperEnsure FFmpeg is installed and working:
ffmpeg -versionSecurity & permissions
Ensure the web server user (e.g., www-data) has:
- Execute permission for whisper and ffmpeg
- Read and write access to resource files and temporary directories
Troubleshooting
- “CUDA not found”: You don’t need GPU support — install the CPU version of PyTorch instead.
- “Command not found”: Make sure Whisper is installed in a directory listed in your $PATH.
- “Permission denied”: Check file and directory permissions for Whisper and FFmpeg.
You’re done!
With Whisper installed and working from the command line, the ResourceSpace plugin will be able to:
- Convert uploaded media to WAV
- Run Whisper transcription locally
- Populate a metadata field with the transcript
- Optionally attach subtitle files as alternative downloads
Plugin configuration
Plugin settings can be configured under Admin > System > Plugins > Whisper > Configuration.
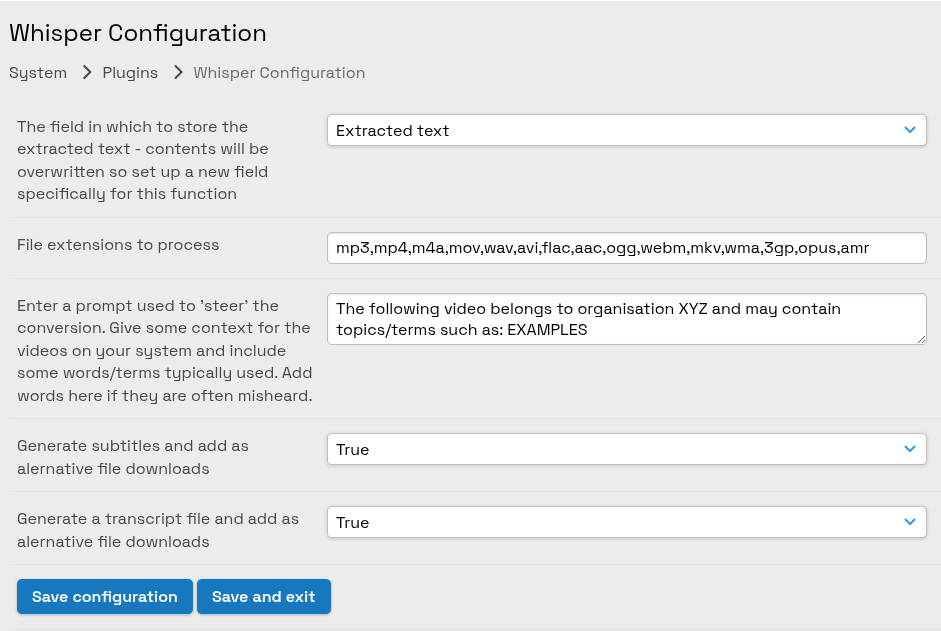
- Select a field in which to store the extracted text.
- Specify which file extensions will be processed - the default covers the most popular types
- Enter a prompt which can help to steer Whisper. You can set context specific to your organisation which will aid in the interpretation of the audio.
- Specify subtitle generation - subtitles in the standard SRT and VTT formats will be added to your resource records as alternative files. The VTT subtitles will be used by ResourceSpace itself when playing the video as an option to the user when clicking the "CC" icon to access closed caption options.
- Specify transcript generation - a plain .txt file will be added to your resource records as an alternative file.
Processing
Whisper will run via the Cron mechanism so if your system is set up correctly the processing will happen automatically, periodically.
You can run the process manually via:
php plugins/whisper/scripts/process.phpCombining with OpenAI GPT
Updates to metadata will trigger OpenAI GPT if configured to take the Whisper field (set in the plugin settings, above) as input. This means you can use GPT to take the extracted text and autmatically generate titles, summaries, descriptions, translations and automatically tag your resources, all using only the audio from the file.
Coming in v11+
A new feature added to v11 will let users run data processing scripts directly from the front-end. This will allow unprocessed resource processing to be triggered via the Offline Jobs page. For more information, see managing offline jobs.