Much more than just data about data
First coined in the 1960’s at MIT, metadata is much more than just its technical definition: data about other data. This is particularly true when it comes to DAM. Used well, metadata frames a digital asset by providing context - this leads to meaning, which is essential when it comes to giving an asset value.
Metadata might have a bit of a reputation for being mundane and linked with boring or repetitive tasks but with the paradigm shift that is generative AI and, in particular, rapidly evolving integrations that can automate metadata creation, conversations around metadata are more interesting than ever.
In the article Zen and the Art of Metadata Maintenance, John W. Warren describes how metadata isn’t just the DNA of a piece of digital content, but also makes up the entire digital content universe:
“[M]etadata is more than just basic descriptive data: a book review about a scholarly monograph becomes part of the monograph’s metadata, while the book review itself is content with its own metadata. The book becomes, in the broadest sense, part of the metadata of each book or article it references; the author forms part of the book’s metadata, and the book becomes part of the author’s own metadata.”
Why metadata is crucial in DAM
Far from just sets of ‘tags’, metadata carries huge importance when it comes to how any object - a book, a digital asset, a piece of music - is understood, interpreted, and given a place to exist within a vast world of content.
The importance of doing this cannot be underrated: one estimate from October 2023 suggested that some 57,000 photographs are now taken per second. Without metadata to ‘frame’ them, it wouldn’t be possible to keep up with which ones are valuable and worth preserving for safe-keeping.
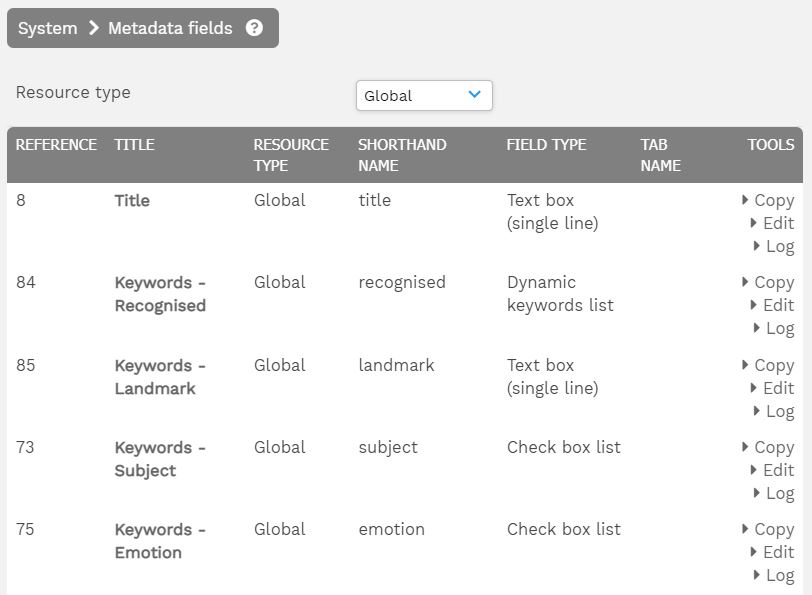
Metadata is used to categorise and describe all kinds of digital assets, from documents and computer files to videos and audio files, and it’s fair to say it is the lifeblood of a Digital Asset Management system.
In some ways, metadata is just as important as the content itself. By providing all of the information about a digital asset, metadata also defines why that asset has value.
Think about a digital image of an ancient artefact. If you don’t know where the artefact was found, how old it is or any of the wider historical context, both the image, and indeed the artefact, are worthless.
From a practical perspective, metadata is what elevates a DAM system above file storage solutions like Google Drive or Microsoft Sharepoint, particularly when it comes to searching for files.
Although assets in file storage systems can be searched for by name, or by text within a file in the case of documents, this functionality pales in comparison compared to a DAM. For example, it’s very difficult to find an image unless you know the file name or where it’s located. In contrast, the search functionality in a DAM works much more like a Google search - and this is all made possible with high quality, relevant metadata.
There are three primary categories of metadata:
Structural
Structural metadata—also known as technical metadata—is more about the file itself rather than what it contains, and it describes how an asset is formatted or configured. For example, some common metadata fields in this category include file size, image dimensions, the date it was created, who uploaded it, or the file format.
Why is structural metadata important?
Structural metadata ensures a file or group of files are used and work correctly. For example, the dimensions of an image will inform where and how that image can be used, while structural metadata will also ensure the pages of an audiobook are properly organised.
Descriptive
Descriptive metadata is used to define the contents of a digital asset, whether that’s specific information to that asset or keywords that describe a broad theme of the asset. For example, an image of a couple holding hands could be tagged with keywords like ‘love’ or ‘relationship’, and/or have a precise description that explains who is in the picture, where they are and what they’re doing. An asset’s title and author/creator are also descriptive metadata.
Why is descriptive metadata important?
Descriptive metadata powers the search functionality of a DAM system. If a Product Marketing Manager of a toy retailer needs to find images of children opening presents for a Christmas marketing campaign, they will use descriptive metadata terms to search the DAM.
Administrative
Administrative metadata is information that helps DAM users to manage an asset, and includes details related to governance, access controls and security, as well as technical data on copyright information, rights management and licence agreements.
Why is administrative metadata important?
Administrative metadata is essential to ensure organisations don’t fall foul of copyright and privacy laws, and it’s used by DAM managers to ensure assets aren’t used for purposes you don’t have permission for, or beyond the date those permissions expire.
Developing an effective metadata workflow
When developing a metadata workflow it’s important to consider the lifecycle of your assets:
-
Creation — which team members need permission for uploading assets into the DAM, and what fields are required in the first instance?
-
Metadata maintenance — who’s responsible for building out additional metadata fields for an asset?
-
Access permissions — how do you define who can use an image and how, and how are these permissions administered?
-
Sharing permissions — where, and with who, should assets be shared?
-
Archival / deletion — how is the process of archiving or removing an asset managed, and what are the triggers for that?
Who’s responsible for each stage? Who has access and what level of permissions do they use? Can any of these stages or responsibilities be automated, for example archiving assets once a set date metadata field has passed? Considering questions like these early on in your project will make sure things run smoothly once up and running.
Adopting a collaborative approach to metadata maintenance can be a good way to establish understanding of the needs and processes for each group or department. This will also promote organisation-wide adoption of the DAM, unlike a top-down approach to enforcing metadata standards. Involving every team from the start will make it easier to review and iterate metadata processes and governance down the line.
However, note that if individual DAM users or specific teams are required to create and update metadata, it should be as simple as possible. What’s more, the DAM system manager will need oversight over these changes. It’s a good idea to ask about any tools that are available to help with tracking changes or making suggestions.
5 metadata best practices
In order to get the most out of your metadata, it’s a good idea to follow some key best practices:
1. Clearly defined metadata field requirements
The amount of information metadata can store about an asset is almost limitless, but that scope and flexibility can cause problems if you haven’t clearly defined the fields you need. Indeed, you might also need to limit the options a user can choose from to ensure consistency. The structure of your metadata is known as ‘metadata schema’.
There are five common metadata standards and schemas:
-
Dublin Core Metadata Initiative (DCMI)—generally used to describe digital and physical resources, DCMI is known for its interoperability and versatility when used alongside other schemas.
-
Metadata Encoding & Transmission Standard (METS)—generally used in digital libraries, METS includes descriptive, administrative and structural metadata. It’s known for its ability to add structure to a digital object.
-
Metadata Object Description Schema (MODS)—created to merge MARC bibliographic standards with Dublin Core’s metadata terms.
-
Text Encoding Initiative (TEI)—primarily used for digital humanities.
- Visual Resources Association (VRA) Core—a standard used to describe images.
To start with, draw up a list of the 10 to 20 most important metadata fields. A good method for ensuring metadata schema is clear and concise is to ask yourself the following two questions:
-
Does this information relate to the usage rights of the digital asset?
-
Will this metadata provide value to the DAM users?
An ideal metadata schema will look different for different organisations and industries, but some of the most common include:
-
Asset name
-
Product numbers
-
Creator, author or owner
-
Asset type
-
The ‘subject’ of the asset, e.g. ‘family’, ‘building’, ‘vehicle’ etc.
2. Each metadata field should have a clear naming convention
A clear and well documented file naming convention is important, but this consistency is just as important for every other metadata field.
For example, with high-level asset categories it's useful to restrict the users' options and set specific choices from a drop-down menu. Otherwise, grammatical inconsistencies like tenses, plurals and typos can really impact the quality of your search results, making the DAM much less efficient.
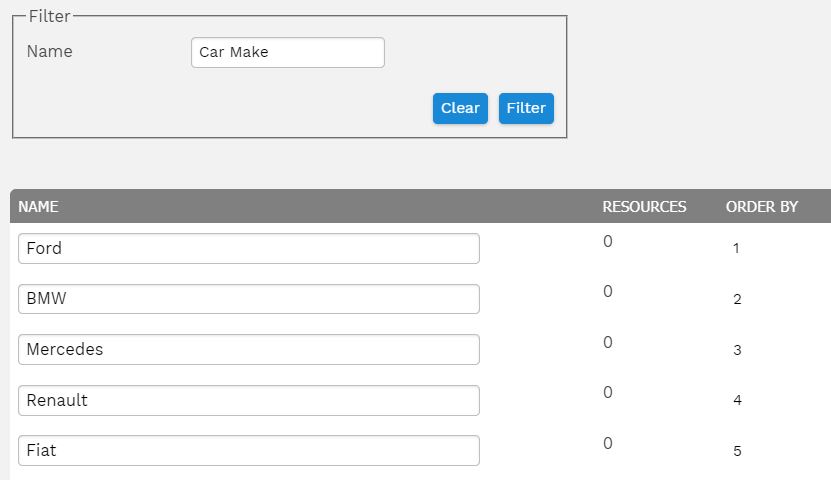
In order for metadata conventions to be useful they need to be agreed on and used by everyone responsible for uploading assets to the DAM. Below are some tips for creating your naming convention:
-
Avoid special characters (! ? @ # $, etc.) as they’re not obvious from a searching perspective, and they also sometimes have specific meanings to an operating system.
-
Consider how file names might be interpreted by someone outside of the company, as sometimes they might appear in embed codes or sharing links.
3. Comprehensive training for DAM users
If used well, a good metadata schema will make all the difference when it comes to being able to locate your assets and fundamentally, draw value from them.
Alongside training users so that they’re familiar with how to add, edit, and maintain accurate metadata, creating a metadata standards document will ensure everyone who'll be using the system understands it and why it's so important. If you’re using ResourceSpace, consider adding a ‘Metadata guide’ dash tile for your admin users along with one or two demo videos, for easy access whenever they’re logged in.
Getting the whole team involved in developing your metadata schema early on in the process will make a big difference for ensuring digital assets are being categorised in the right way.
A detailed, shared, metadata standards document will also be an advantage in the future should there be changes to who’s responsible for administering your DAM.
4. Refine metadata over time
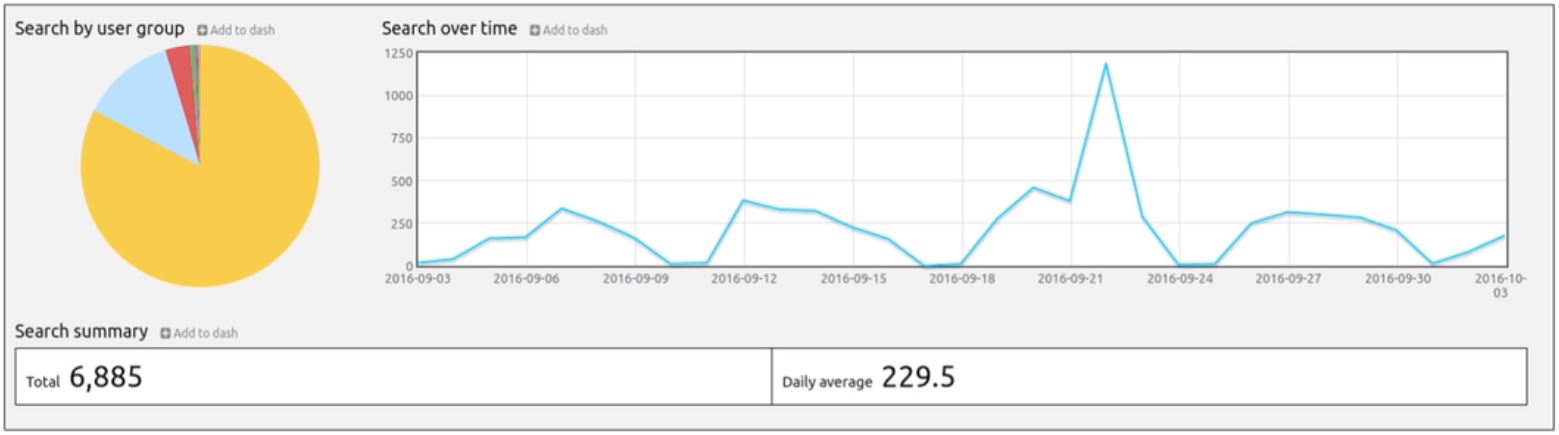
As your DAM grows and evolves, so should the metadata schema, and it’s important to continually refine what's used, removing fields that the team aren't getting use out of and adding new ones if they’re needed or requested.
Most DAMs provide reporting on user search activity which is crucial for identifying gaps in the schema, or where people are wasting time entering data that isn't searched for. You’ll also be able to see keywords being searched for that don't return any results, which might be a sign your metadata hasn't been set up correctly, or that your DAM doesn't have the resources people are looking for.
5. Don’t overrely on manual metadata inputs
When used correctly, metadata will make the job of a Digital Asset Manager significantly easier, but if DAM users are having to manually enter multiple metadata fields every time an asset is uploaded it’s going to waste a lot of time.
A certain degree of manual entry will probably always be necessary, especially when it comes to contextual metadata, such as names, SKU numbers, ID numbers etc. However, if your DAM system allows, make sure you’re leveraging automated tagging to reduce it as much as possible and ensure DAM users are more likely to complete the required contextual fields.
How does ResourceSpace use metadata
Metadata is the primary method of organising and searching for resources in ResourceSpace, while there are also advanced metadata tools to provide depth to the structuring of your files.
Fixed metadata
Metadata allows you to classify resources in many different ways, but this freedom comes with challenges, particularly around consistency of tagging.
In ResourceSpace you can retain control of metadata inputs by restricting the fields available to complete. For example, you can create drop-down lists, radio select buttons, check boxes or category trees, rather than ‘free text’ fields.


AI-automated metadata tagging and processing
Our AI-automated tagging features save a lot of time when uploading assets, with recognition tools automatically detecting objects, items, faces and places present in visual media, and prompting appropriate keywords to be suggested. Tools like Google Vision can place identifiable text into a separate field, while specific people can be identified after ResourceSpace learns from existing tagged faces.
We also integrate with OpenAI’s GPT-4 language model. When we launched our GPT-3 integration, ResourceSpace could process text from an input field and auto-populate an output field. Instructions can then be set based on that output field, for example:
-
‘Translate this text into French.’
-
‘List the critical keywords from this text.’
-
‘Convert this text into compelling marketing copy.’
Since November 2023 and the introduction of GPT-4 multimodal capability, it’s now possible to use an image itself as the ‘prompt’ to create all manner of metadata entries. For example, GPT can be used to create descriptions of an image with no other input than the image itself:


Embedded data extraction
ResourceSpace also utilises Exiftool, a third-party tool which extracts data embedded within an image and automatically uploads it into the resource metadata. This is highly configurable, can apply to any metadata stored within a file, and can be configured by an administrator.
Do you want to find out more about how metadata powers ResourceSpace?
Book a free, 30-minute demo and we’ll walk you through the platform’s metadata functionality and how it will transform your Digital Asset Management.